Deep Learning Basic 02 - Historical Review
in AI Tech on ⁃ AI Basic

Intro
- 딥러닝의 역사
- 2012년부터 2020년까지의 패러다임
- Intro
- 1. AlexNet
- 2. DQN
- 3. Encoder / Decoder
- 4. Adam Optimizer
- 5. GAN
- 6. Residual Networks
- 7. Transformer
- 8. BERT
- 9. BIG Language Models
- 10. Self Supervised Learning (SimCLR)
1. AlexNet
이미지가 들어왔을 때,분류하는 것이 목표, AlexNet 이후 머신러닝의 판이 바뀌기 시작함

2. DQN
알파고를 만든 알고리즘을 만든 회사 딥마인드 → 구글 인수 (구글 딥마인드)- 아래 이미지는
큐러닝의 방법론을 이용해서 딥러닝에 접목해서 만든 게임

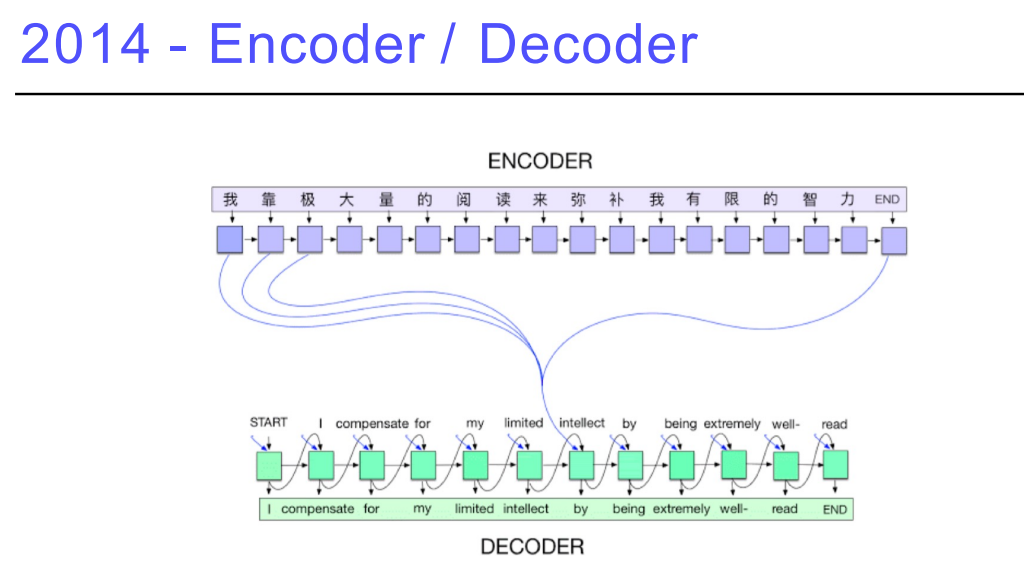
3. Encoder / Decoder
구글번역에 활용되는 방법론, 단어의 연속이 주어졌을 때 이를 잘 표현해서 다음 언어를 뱉어주는 것- 단어의 시퀀스가 주어지면, 어떤 벡터에 인코딩하고, 다른 언어의 시퀀스를 만들어 주는 것
- 기계어 번역의 트렌드가 많이 바뀜
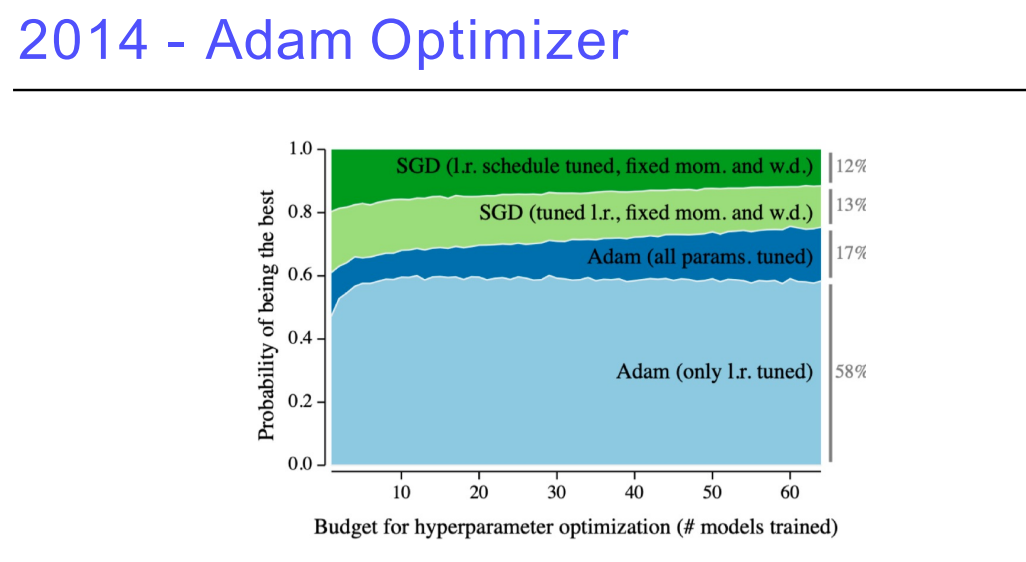
4. Adam Optimizer
딥러닝을 학습시킬 때, Adam을 디폴트로 사용 → 그 이유는 Adam이 평균적으로 결과가 매우 잘 나오기 때문
5. GAN
- GAN의 목표 :
이미지와텍스트를 어떻게 만들어낼지? (생성모델)

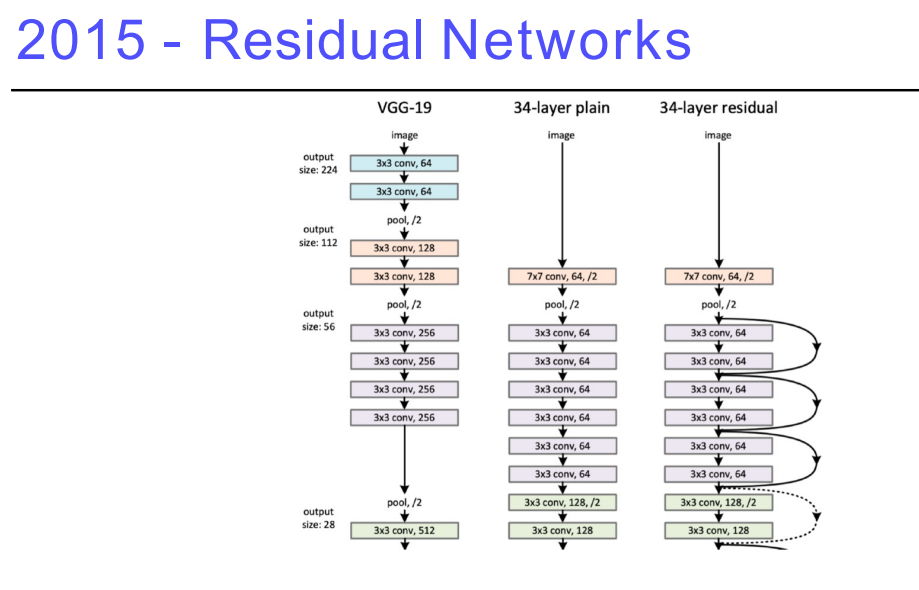
6. Residual Networks
딥러닝의 딥러닝이 가능해짐 → 마치 뇌의 신경망처럼네트워크를 깊게쌓았기 때문- 과거 네트워크를 너무 깊게 쌓으면, 테스트를 했을 때 성능이 잘 안나온다는 이야기가 있었지만 Residual이 나오고 트렌드가 바뀜
7. Transformer
- Attention is all you need.

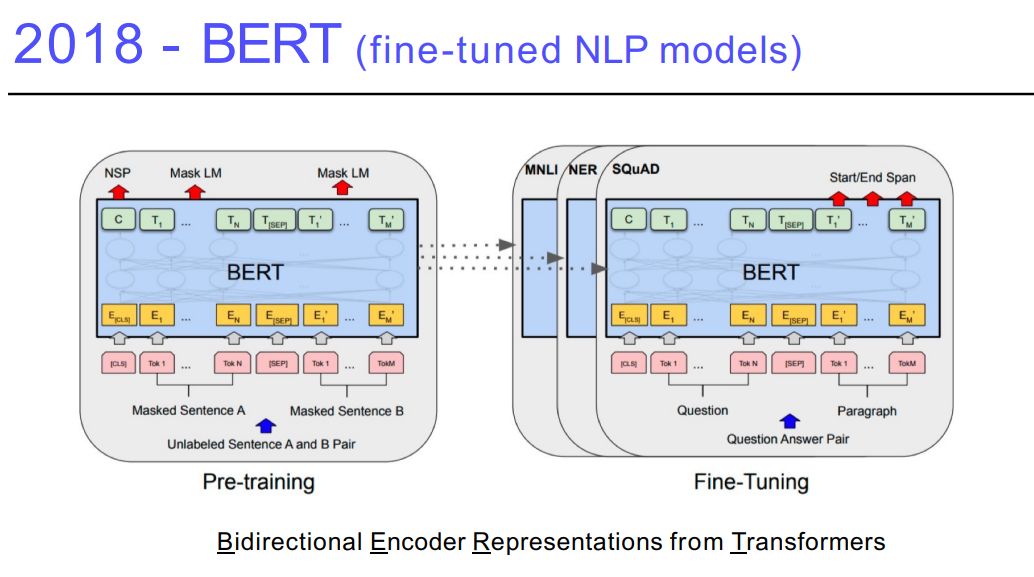
8. BERT
NLP는Language 모델을 학습- Language 모델은 다음 단어가 무엇이 나올지 맞추는 것 → 문장 생성 → 프로그램 생성 → 글 작성
- 날씨를 예측하거나 좋은 뉴스 기사를 만드는 네트워크를 만들고 싶지만, 뉴스 데이터가 필요함
- 하지만 학습 데이터를 찾기 어렵기 때문에 다양한 단어, 말뭉치(코퍼스)를 이용해
fine-tuning
9. BIG Language Models
- BERT의 끝판왕,
약간의 fine-tuning으로 문장, 프로그램, 표, 시퀀스 모델들을 만들 수 있음175억 개의 파라미터로 이루어져 있음

10. Self Supervised Learning (SimCLR)
- 이미지 분류와 같은 분류 문제를 풀 때 학습 데이터가 한정적일 경우, model과 loss function을 바꿔가며 여러 좋은 결과를 내는 것이 일반적
- 여기서는 학습 데이터 외, 라벨을 모르는
Unsuperviser data를 활용 → 라벨이 없는 구글 내 이미지들을 학습에 같이 활용 → 어떻게 하면 이미지를 컴퓨터가 잘 이해할 수 있는 벡터로 바꿀 수 있을지, 결과론적으로 좋은 학습함으로써 진짜 풀고자하는 분류문제를 풀고자 하는 것이 논문의 흐름 —- 주어진 학습 데이터 외, 데이터를 추가로 활용해서 결과를 얻는 것이 목적
- 학습 데이터를 도메인 지식을 통해 추가로 만들어 내, 학습 데이터를 증폭시켜 학습

소통은 제가 공부하고 공유하는 원동력이 됩니다.
해당 글이 도움이 되셨다면 소중한 격려와 응원 부탁드립니다 ☺️
해당 글이 도움이 되셨다면 소중한 격려와 응원 부탁드립니다 ☺️
