KoBERT를 활용한 감정분류 모델 구현 with Colab

안녕하세요, Daisy 입니다 ☺️
SKT Brain에서 개발한 KoBERT 오픈소스 코드를 활용해
Google Colab에서 감정분류 모델을 구현해보았으며 그 과정을 소개하고자 합니다.
- 1. About KoBERT
- 2. 활용 데이터셋 소개
- 3. Setting Environment (Colab)
- 4. Data Preprocessing (데이터 전처리)
- 5. KoBERT 모델 구현
- 6. Train
- 7. Test
- 8. Conclusion
1. About KoBERT
먼저 KoBERT (Korean Bidirectional Encoder Representations from Transformers)는
기존 BERT의 한국어 성능 한계를 극복하기 위해 SKT Brain에서 개발한 모델입니다.
이러한 KoBERT는 위키피디아나 뉴스 등에서 수집한 수백만 개 한국어 문장의 대규모 말뭉치 (Corpus)를 학습하였으며,
한국어의 불규칙한 언어 변화의 특성을 반영하기 위해 데이터 기반 토큰화 (Tokenization) 기법을 적용하여 기존 대비 27%의 토큰만으로 2.6% 이상의 성능 향상을 이끌어 낸 모델 입니다.
대량의 데이터를 빠른시간에 학습하기 위해 링 리듀스(ring-reduce) 기반 분산 학습 기술을 사용하여 십억 개 이상의 문장을
다수의 머신에서 빠르게 학습하고, 파이토치(PyTorch), 텐서플로우(TensorFlow), ONNX, MXNet을 포함한 다양한 딥러닝 API를 지원함으로써 많은 분야에서 언어 이해 서비스 확산에 기여하고 있습니다.
Pre-trained된 KoBERT는 그대로 사용할 수도 있지만,
본 포스팅처럼 목적에 맞게 Fine-tuning하여 원하는 방향으로 조정할 수도 있습니다.
2. 활용 데이터셋 소개
AI Hub내 KAIST 인공지능연구소에서 구축한 감정 분류를 위한 대화 음성 데이터셋에서 ‘5차년도 2차 CSV’를 활용하였습니다.
해당 데이터는 감성대화 어플리케이션을 이용하여 수집되었으며
일정 기간동안 사용자들이 어플리케이션과 자연스럽게 대화하고 수집된 데이터를 정제 작업을 거쳐 선별한 데이터로,
총 7가지 감정(happiness, angry, disgust, fear, neutral, sadness, surprise)에 대해 라벨링이 되어 있습니다.
3. Setting Environment (Colab)
모델을 구현하기 앞서 환경설정을 진행해보도록 합니다.
해당 사양은 KoBERT 오픈소스 내 requirements.txt를 참고하였습니다.
# Colab 환경 설정
# requirements : https://github.com/SKTBrain/KoBERT/blob/master/kobert_hf/requirements.txt
!pip install gluonnlp pandas tqdm
!pip install mxnet
!pip install sentencepiece==0.1.91
!pip install transformers==4.8.2
!pip install torch
다음으로는 깃허브 내 파일을 Colab으로 가져옵니다.
# https://github.com/SKTBrain/KoBERT 의 파일들을 Colab으로 다운로드
!pip install git+https://git@github.com/SKTBrain/KoBERT.git@master
그 다음으로는 해당 라이브러리들을 import 해줍니다.
# koBERT
from kobert.utils import get_tokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
# Transformers
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
# Setting Library
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
import pandas as pd
다음 코드를 통해 Colab의 GPU를 활용합니다.
device = torch.device("cuda:0")
CPU를 활용하고 싶다면, 다음과 같이 코드를 변경해주시면 됩니다.
device = torch.device("cpu")
다음 코드를 통해 BERT 모델, Vocabulary를 불러옵니다.
# BERT 모델, Vocabulary 불러오기
bertmodel, vocab = get_pytorch_kobert_model(cachedir=".cache")
마지막으로 AI Hub에서 다운로드받은 파일을 Colab으로 불러와주면 초기 세팅은 완료입니다.
Local 파일을 Colab으로 업로드해준 뒤, 해당 path를 지정해주면 됩니다.
# [AI Hub] 감정 분류를 위한 대화 음성 데이터셋
data = pd.read_csv("/content/5차년도_2차.csv", encoding='cp949')
4. Data Preprocessing (데이터 전처리)
먼저 데이터를 전체적으로 살펴보겠습니다.
data(head)와 data.shape를 통해 ‘19,374개의 행과 15개의 열’로 다음과 같이 이루어져 있는 것을 확인하였습니다.

다음으로는 data['상황'].unique() 를 통해, 앞서 데이터 소개에 설명된 7개의 감정 class를 확인합니다.
data['상황'].unique()
>>> array(['happiness', 'neutral', 'sadness', 'angry', 'surprise', 'disgust','fear'], dtype=object)
이제 이 7개의 감정 class를 다음 코드를 통해 숫자로 바꿔보겠습니다.
# 7개의 감정 class → 숫자
data.loc[(data['상황'] == "fear"), '상황'] = 0 # fear → 0
data.loc[(data['상황'] == "surprise"), '상황'] = 1 # surprise → 1
data.loc[(data['상황'] == "angry"), '상황'] = 2 # angry → 2
data.loc[(data['상황'] == "sadness"), '상황'] = 3 # sadness → 3
data.loc[(data['상황'] == "neutral"), '상황'] = 4 # neutral → 4
data.loc[(data['상황'] == "happiness"), '상황'] = 5 # happiness → 5
data.loc[(data['상황'] == "disgust"), '상황'] = 6 # disgust → 6
그리고 data['상황'].unique()코드로 다시 확인해보면, 정상적으로 바뀐 것을 확인할 수 있습니다.
>>> array([5, 4, 3, 2, 1, 6, 0], dtype=object)
이제 이를 토대로 발화문과 상황 컬럼의 값들이 쌍으로 이뤄진 데이터셋을 생성해보겠습니다.
코드는 다음과 같습니다.
# [발화문, 상황] data_list 생성
data_list = []
for ques, label in zip (data['발화문'], data['상황']):
data = []
data.append(ques)
data.append(str(label))
data_list.append(data)
아래와 같이 정상적으로 데이터셋이 구축된 것을 확인할 수 있습니다.
print(data)
print(data_list[:10])
>>> ['걱정해줘서 고마워.', '6']
>>> [['헐! 나 이벤트에 당첨 됐어.', '5'], ['내가 좋아하는 인플루언서가 이벤트를 하더라고. 그래서 그냥 신청 한번 해봤지.', '5'],
['한 명 뽑는 거였는데, 그게 바로 내가 된 거야.', '5'], ... (생략)]
4-1. Split train & test data set
이제 data_list 데이터셋을 sklearn을 통해 train & test로 나눠봅니다.
from sklearn.model_selection import train_test_split
dataset_train, dataset_test = train_test_split(data_list, test_size = 0.2, shuffle = True, random_state = 32)
각각 전체 대비 80%, 20% 비율로 나뉜 것을 확인할 수 있습니다.
print(len(dataset_train), len(dataset_test))
>>> 15499 3875
4-2. 데이터셋 토큰화
다음으로는 데이터셋을 토큰화해보도록 하겠습니다.
앞서 환경설정에서 가져온 vocab을 활용해 tokenizer를 먼저 불러옵니다.
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower = False)
tokenization, int encoding, padding하는 BERTDataset 함수는 다음과 같이 구성되며,
KoBERT 오픈소스 내 예제코드를 참고하였습니다.
# BERTDataset : 각 데이터가 BERT 모델의 입력으로 들어갈 수 있도록 tokenization, int encoding, padding하는 함수
# 출처 : https://github.com/SKTBrain/KoBERT/blob/master/scripts/NSMC/naver_review_classifications_pytorch_kobert.ipynb
class BERTDataset(Dataset):
def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, vocab, max_len, pad, pair):
transform = nlp.data.BERTSentenceTransform(
bert_tokenizer, max_seq_length=max_len,vocab = vocab, pad = pad, pair = pair)
self.sentences = [transform([i[sent_idx]]) for i in dataset]
self.labels = [np.int32(i[label_idx]) for i in dataset]
def __getitem__(self, i):
return (self.sentences[i] + (self.labels[i], ))
def __len__(self):
return (len(self.labels))
4-3. Setting parameters
다음으로는 parameter를 지정해보겠습니다.
KoBERT 오픈소스 예제의 parameter 값과 동일하게 설정하였습니다.
# parameter 값 출처 : https://github.com/SKTBrain/KoBERT/blob/master/scripts/NSMC/naver_review_classifications_pytorch_kobert.ipynb
max_len = 64
batch_size = 64
warmup_ratio = 0.1
num_epochs = 5
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5
4-4. Data tokenization, int encoding, padding
이제 BERTDataset 함수에 sklearn을 통해 train & test으로 나눈 데이터를 입력합니다.
# BERTDataset : 각 데이터가 BERT 모델의 입력으로 들어갈 수 있도록 tokenization, int encoding, padding하는 함수
data_train = BERTDataset(dataset_train, 0, 1, tok, vocab, max_len, True, False)
data_test = BERTDataset(dataset_test, 0, 1, tok, vocab, max_len, True, False)
마지막으로 torch 형식으로 변환해주면 모델에 입력할 데이터셋의 전처리는 완료입니다.
# torch 형식의 dataset을 만들어 입력 데이터셋의 전처리 마무리
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size = batch_size, num_workers = 5)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size = batch_size, num_workers = 5)
5. KoBERT 모델 구현
이제 본격적으로 KoBERT 모델을 구현해보겠습니다.
다음의 코드들은 KoBERT 오픈소스 내 예제코드를 참고하였습니다.
# KoBERT 오픈소스 내 예제코드 : https://github.com/SKTBrain/KoBERT/blob/master/scripts/NSMC/naver_review_classifications_pytorch_kobert.ipynb
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size = 768,
num_classes = 7, # 감정 클래스 수로 조정
dr_rate = None,
params = None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size , num_classes)
if dr_rate:
self.dropout = nn.Dropout(p = dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device),return_dict = False)
if self.dr_rate:
out = self.dropout(pooler)
return self.classifier(out)
그리고 이 BERTClassifier 함수에 초기 환경설정에서 가져온 bertmodel을 불러오고,
.to(device) 를 통해 GPU 사용을 설정한 model 함수를 정의합니다.
# BERT 모델 불러오기
model = BERTClassifier(bertmodel, dr_rate = 0.5).to(device)
optimizer와 schedule을 설정합니다.
# optimizer와 schedule 설정
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr = learning_rate)
loss_fn = nn.CrossEntropyLoss() # 다중분류를 위한 loss function
t_total = len(train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps = warmup_step, num_training_steps = t_total)
마지막으로 정확도 측정을 위한 calc_accuracy 함수를 다음과 같이 정의합니다.
# calc_accuracy : 정확도 측정을 위한 함수
def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc
train_dataloader
6. Train
이제 본격적으로 모델을 훈련해보겠습니다.
train_history = []
test_history = []
loss_history = []
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
# print(label.shape, out.shape)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
train_history.append(train_acc / (batch_id+1))
loss_history.append(loss.data.cpu().numpy())
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
# train_history.append(train_acc / (batch_id+1))
# .eval() : nn.Module에서 train time과 eval time에서 수행하는 다른 작업을 수행할 수 있도록 switching 하는 함수
# 즉, model이 Dropout이나 BatNorm2d를 사용하는 경우, train 시에는 사용하지만 evaluation을 할 때에는 사용하지 않도록 설정해주는 함수
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} test acc {}".format(e+1, test_acc / (batch_id+1)))
test_history.append(test_acc / (batch_id+1))
위 코드를 실행 후 15분 정도 기다리면 다음과 같이 모델 학습을 완료합니다.
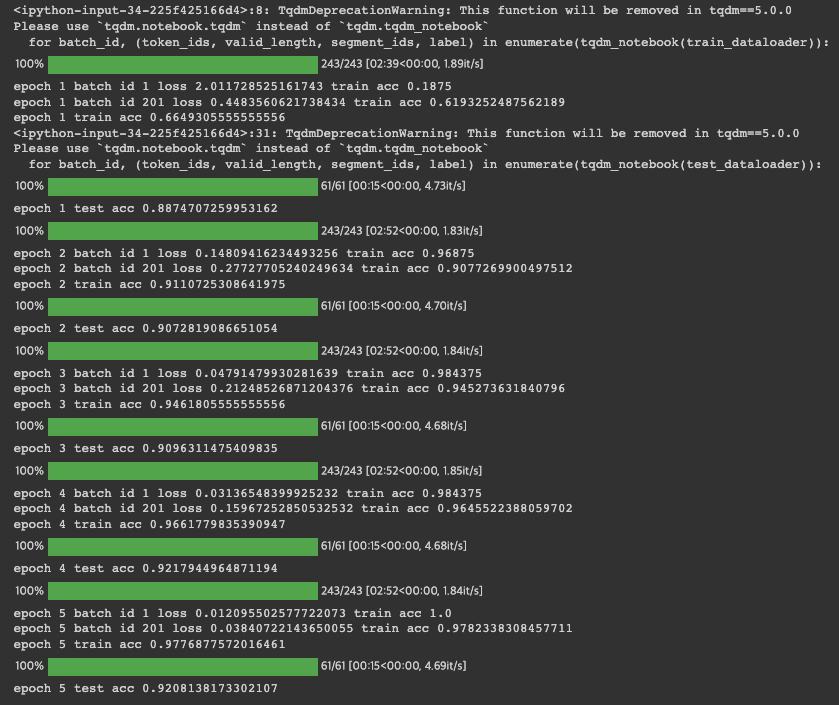
각각 train과 test data에 대하여, 다음과 같은 높은 정확도 결과를 보여주었습니다.
epoch 5 train acc 0.9776877572016461
epoch 5 test acc 0.9208138173302107
7. Test
다음은 Train된 모델을 Test 해보겠습니다.
아래 Test 코드는 해당 블로그를 참고하였습니다.
# predict : 학습 모델을 활용하여 다중 분류된 클래스를 출력해주는 함수
# 코드 출처 : https://hoit1302.tistory.com/159
def predict(predict_sentence): # input = 감정분류하고자 하는 sentence
data = [predict_sentence, '0']
dataset_another = [data]
another_test = BERTDataset(dataset_another, 0, 1, tok, vocab, max_len, True, False) # 토큰화한 문장
test_dataloader = torch.utils.data.DataLoader(another_test, batch_size = batch_size, num_workers = 5) # torch 형식 변환
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_dataloader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_eval = []
for i in out: # out = model(token_ids, valid_length, segment_ids)
logits = i
logits = logits.detach().cpu().numpy()
if np.argmax(logits) == 0:
test_eval.append("공포가")
elif np.argmax(logits) == 1:
test_eval.append("놀람이")
elif np.argmax(logits) == 2:
test_eval.append("분노가")
elif np.argmax(logits) == 3:
test_eval.append("슬픔이")
elif np.argmax(logits) == 4:
test_eval.append("중립이")
elif np.argmax(logits) == 5:
test_eval.append("행복이")
elif np.argmax(logits) == 6:
test_eval.append("혐오가")
print(">> 입력하신 내용에서 " + test_eval[0] + " 느껴집니다.")
마지막으로 다음 코드를 통해 텍스트를 입력하면 해당 텍스트가 predict 함수를 거쳐 결과값을 출력합니다.
만약 input에 0을 입력하면 종료됩니다.
# 질문에 0 입력 시 종료
end = 1
while end == 1 :
sentence = input("하고싶은 말을 입력해주세요 : ")
if sentence == "0" :
break
predict(sentence)
print("\n")
해당 코드를 실행하면 다음과 같이 텍스트를 입력할 수 있고,
다음과 같이 감정분류를 통해 7개의 라벨 중 하나를 출력하는 결과를 확인할 수 있습니다.

8. Conclusion
KoBERT를 활용해 7개의 감정분류 task를 수행해본 결과 준수한 성능을 확인할 수 있었습니다.
다만 역시 텍스트만으로는 감정분류를 수행하는 것은 한계가 있다고 생각합니다.
예를 들면, 위처럼 헐이라는 단어를 입력했을 때 기대한 출력 값은 놀람 혹은 중립이었다면, 해당 모델은 행복이라는 결과를 출력하였습니다. 때문에 상황에 대한 정보가 담긴 음성, 이미지, 영상과 함께 분석을 진행해야 더 정확한 결과가 나올 것으로 생각합니다. 따라서, 다음은 multi-modal 감정분석을 시도할 계획입니다 ☺️
추가로 제 GitHub에 전체 코드를 업로드하였으니, 전체 코드를 확인하고 싶으시면 해당 GitHub를 확인해주세요.
마지막으로 KoBERT의 개발과 이를 오픈해주신 SKT Brain에 감사의 말씀을 드립니다.
저도 언젠가 더 나은 삶과 세상을 위한 AI 기술을 개발하고 오픈하는 기술자를 다짐하며 해당 포스팅을 마무리하겠습니다.
해당 글이 도움이 되셨다면 소중한 격려와 응원 부탁드립니다 ☺️
